Abstract
How do AI models perceive social signals in visual scenes, and how closely do their representations align with human perceptions? While recent vision models have achieved remarkable performance on traditional computer vision benchmarks, their ability to capture human-like social understanding remains unclear. We investigate this question by collecting a large-scale benchmark of 49,000+ human similarity judgments on 250 video clips depicting diverse social interactions. Surprisingly, we find that language embeddings derived from human-written captions align better with human similarity judgments than state-of-the-art video models, suggesting a significant gap in how video models process social information.
To address this gap, we propose a behavior-guided fine-tuning approach that aligns video model representations with human social perception. Using a hybrid triplet-RSA objective with low-rank adaptation (LoRA), we fine-tune a TimeSformer video model to match human pairwise similarity judgments. Our results demonstrate that this targeted fine-tuning significantly improves alignment with human social perception while maintaining strong performance on downstream tasks. We further show that our approach enables better encoding of social-affective attributes and exhibits promising transfer learning capabilities.
This work establishes a new benchmark for evaluating and improving how AI systems understand social interactions, offering a path toward more human-aligned video understanding models.
Overview
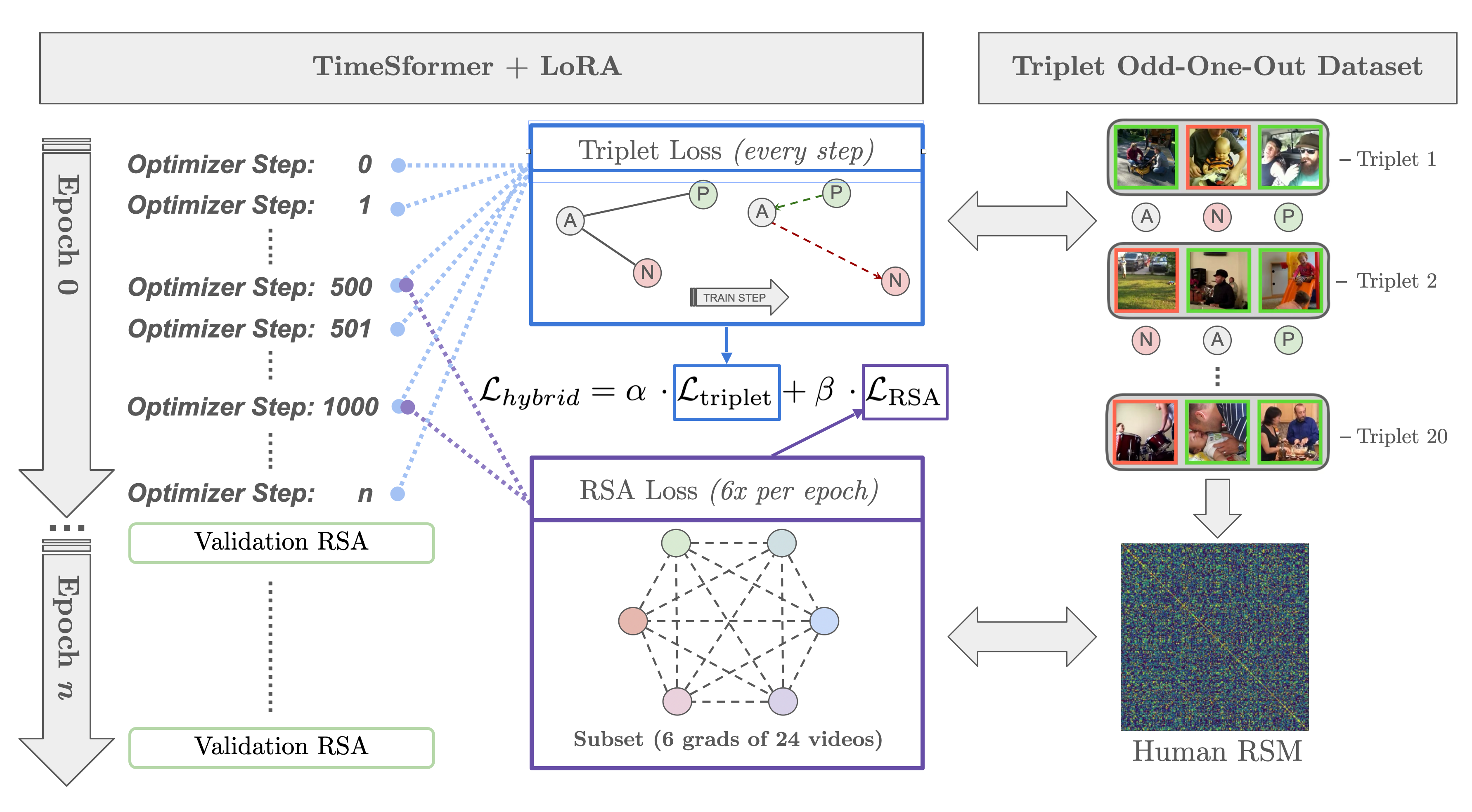
Behavior-Guided Fine-Tuning Framework. We fine-tune a pre-trained video model (TimeSformer) using human similarity judgments as supervision. The model learns to align its pairwise video representations with human perceptual similarity through a hybrid triplet-RSA loss, using LoRA for efficient parameter updates.
Human Similarity Judgments
Triplet Odd-One-Out Task. We collected 49,000+ similarity judgments from human participants who viewed triplets of social videos and selected the odd-one-out. This large-scale dataset reveals how humans organize and perceive social interactions.
Model Alignment Results
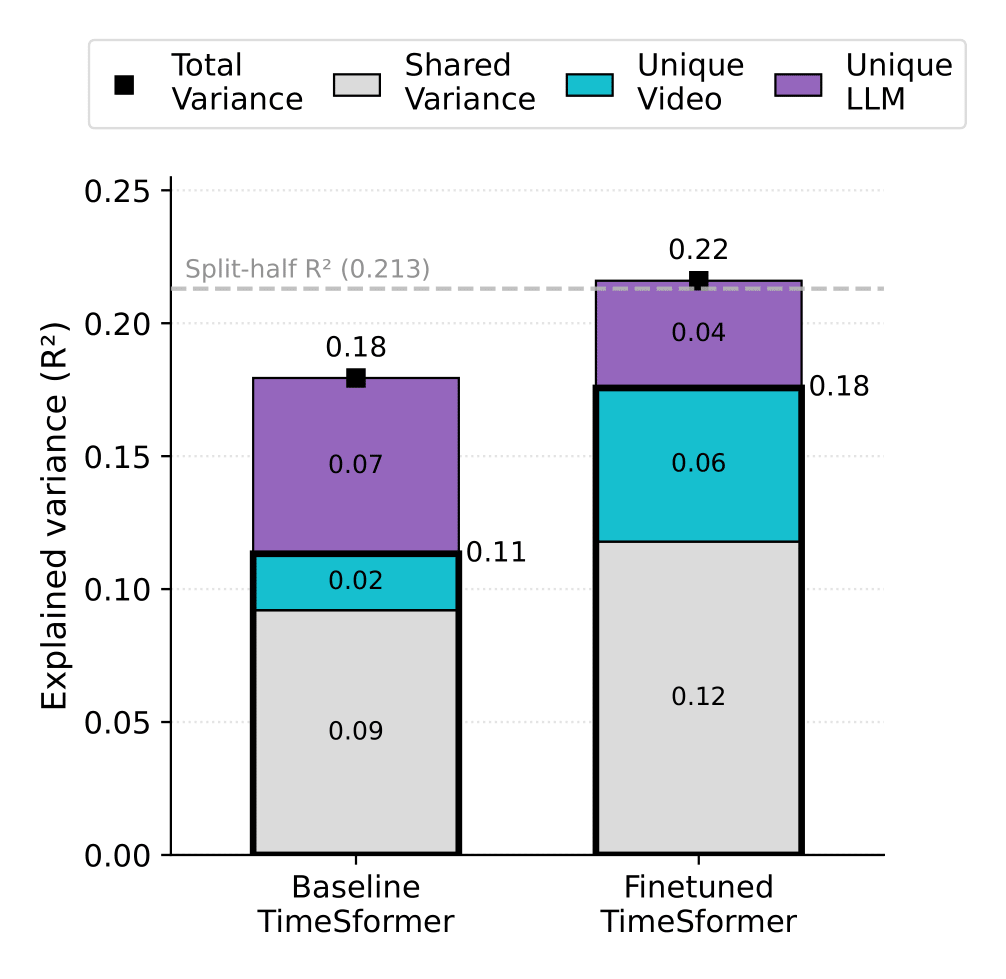
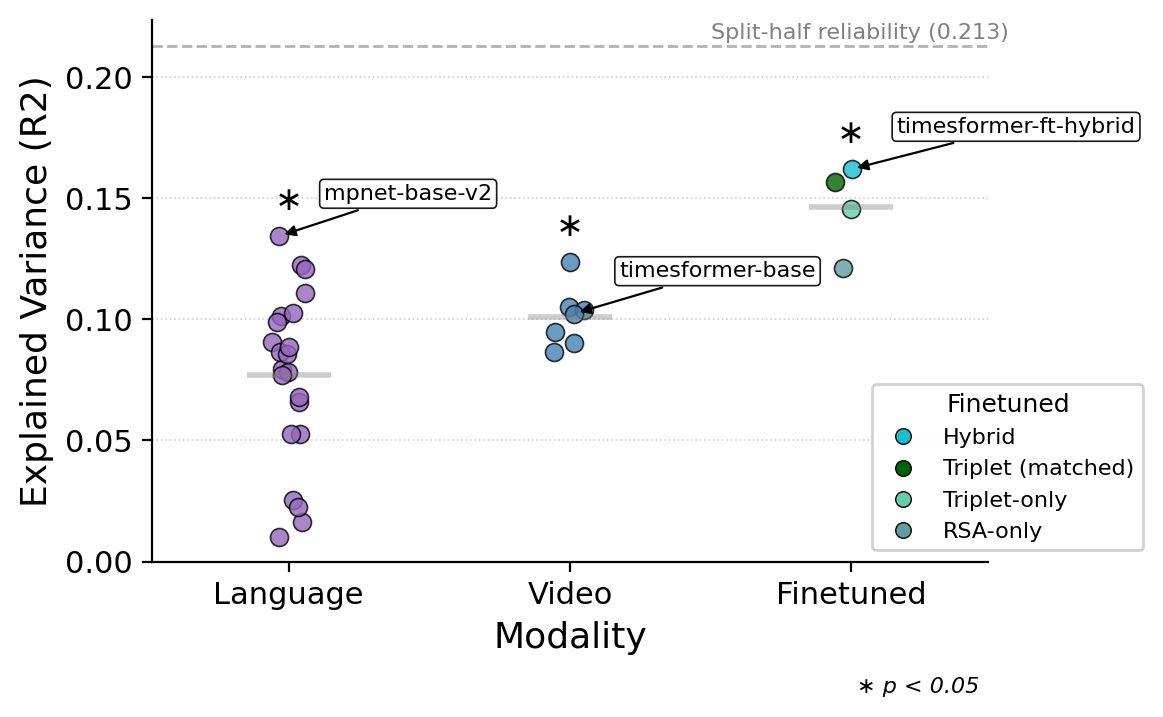
Improved Alignment with Human Perception. Our behavior-guided fine-tuning significantly improves the correlation between video model representations and human similarity judgments. The fine-tuned model shows stronger alignment across multiple evaluation metrics compared to the baseline pre-trained model.
Fine-Tuning Methodology
Hybrid Triplet-RSA Loss. We combine a triplet loss that encourages the model to match human odd-one-out choices with an RSA loss that aligns the full representational geometry. Low-rank adaptation (LoRA) enables efficient fine-tuning with minimal parameter updates.
Key Findings
Our work reveals several important insights:
(1) Language models outperform video models: Human-written captions processed by language models align better with human social perception than state-of-the-art video models, highlighting a critical gap in video understanding.
(2) Behavior-guided fine-tuning improves alignment: Targeted fine-tuning using human similarity judgments significantly improves video model alignment with human social perception, bridging the gap between AI and human understanding.
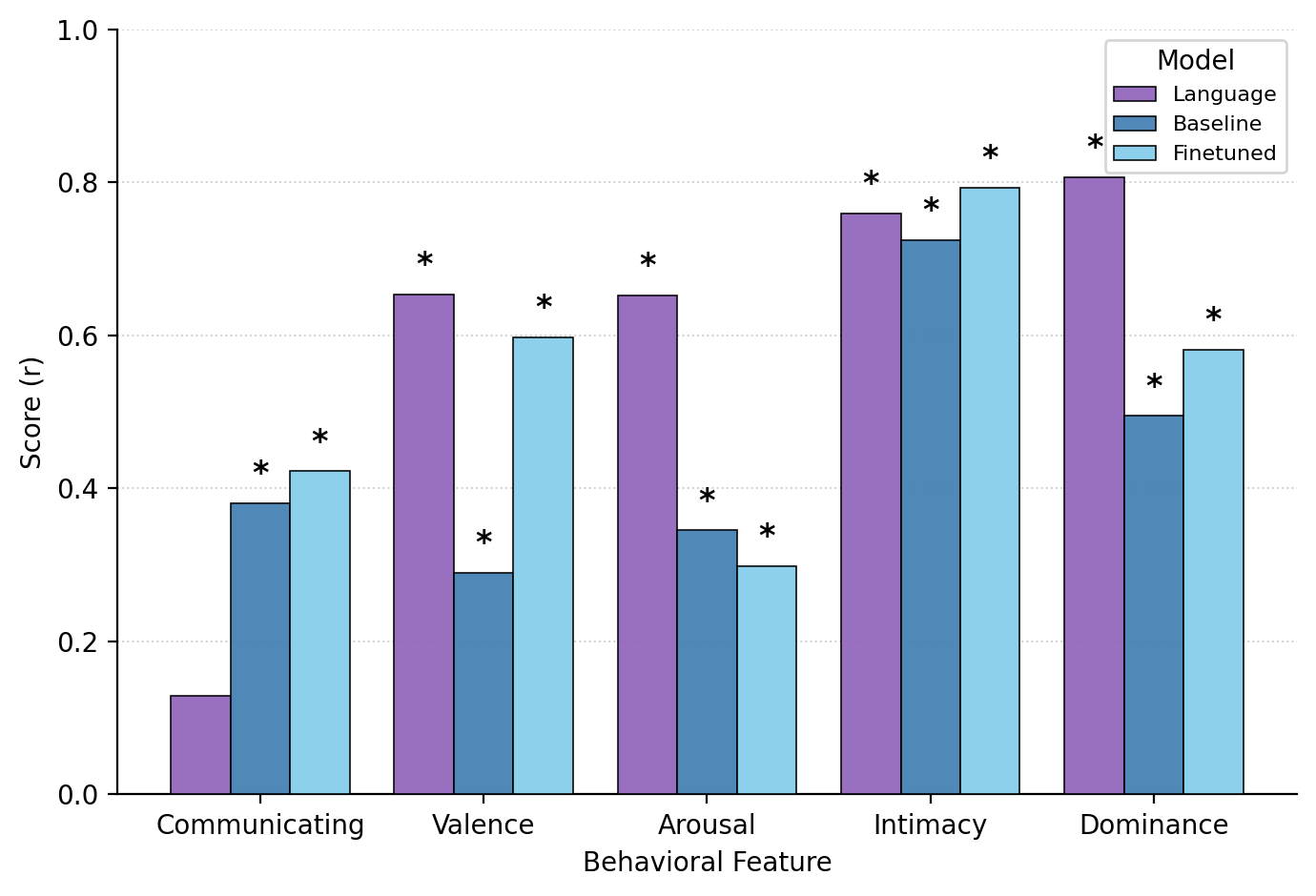
(3) Transfer learning capabilities: Models fine-tuned on human judgments show improved encoding of social-affective attributes and generalize to related social understanding tasks.
(4) New benchmark for social video understanding: Our dataset of 49,000+ similarity judgments provides a valuable resource for training and evaluating future models of social perception.
Citation
Garcia, K., & Isik, L. (2025). Aligning Video Models with Human Social Judgments via Behavior-Guided Fine-Tuning. arXiv preprint arXiv:2510.01502.