Look, Then Speak: Social Tokens for
Grounding LLMs in Visual Interactions
Abstract
Social interactions remain a major challenge for large language models (LLMs), which struggle to incorporate visual context and social cues. We propose social tokens, a lightweight mechanism that introduces socially grounded visual information into a frozen LLM. To construct these tokens, we first fine-tune a visual encoder on videos of social interactions to learn embeddings that capture socially relevant cues. A small MLP then projects these embeddings into the LLM's embedding space, where they are inserted into the input sequence as local and global summaries of the scene. This representational alignment enables the LLM to condition generation on social context without updating its parameters. Empirically, social tokens substantially reduce perplexity on social dialogue and caption datasets, improve alignment with human social judgments, and receive high attention weights during socially salient segments, underscoring both their utility and interpretability.
Injecting social understanding into LLMs
via social tokens
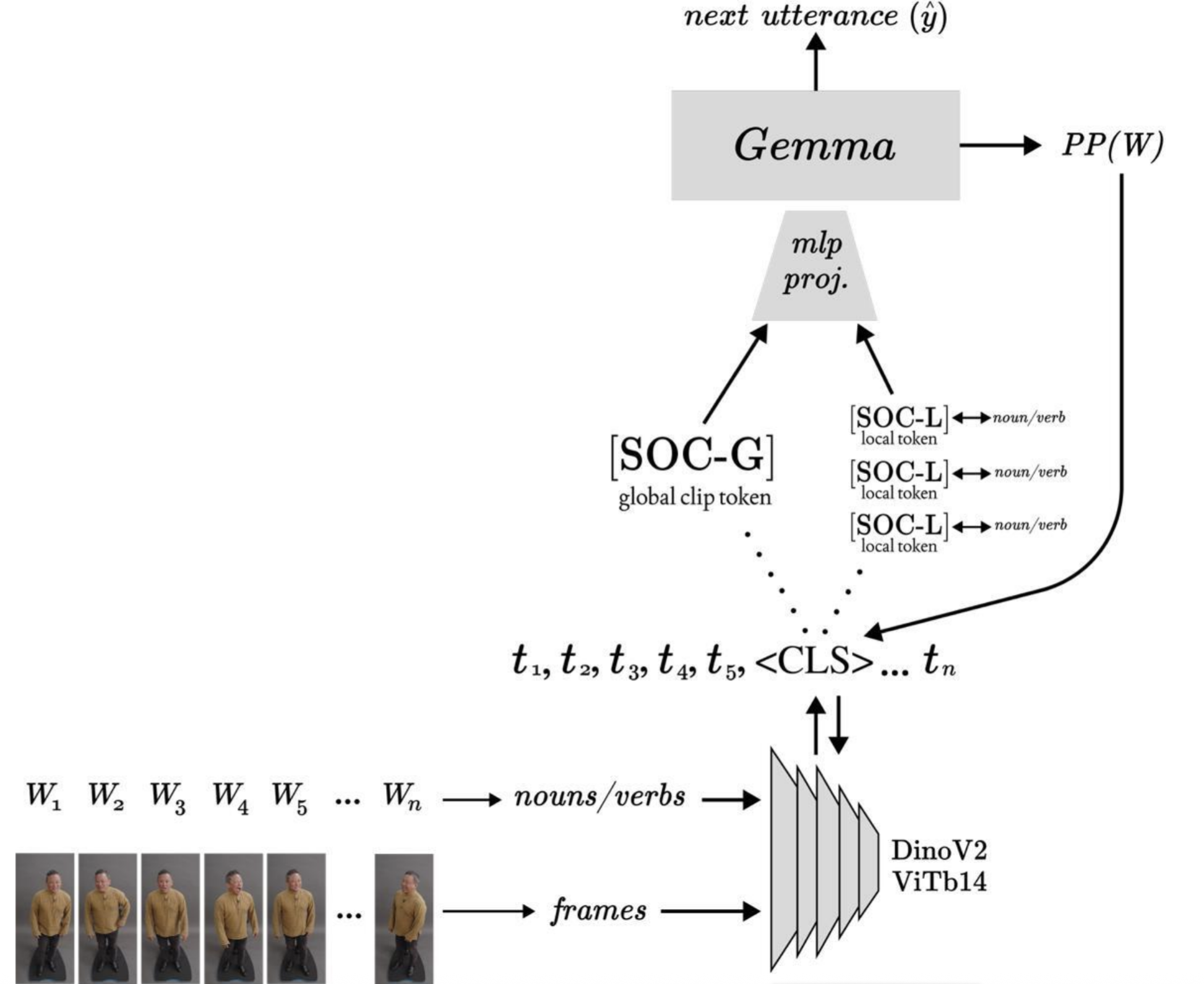
Social tokens are projected embeddings produced by modality-specific encoders (e.g., vision; extensible to audio) and inserted into an LLM (e.g., Gemma). Given a video and its timealigned transcript, we POS-tag the text to select nouns and verbs using the spaCy parser, retrieve the temporally nearest frame for each selected word, and encode it with DINOv2. The frame \(\texttt{[CLS]}\) embedding is projected by a learned MLP into the LLM's embedding space to form a local social token \(\texttt{[SOC-L]}\), which is inserted immediately after the corresponding text token. A global token \(\texttt{[SOC-G]}\) is computed by averaging the local token vectors and is prepended to the sequence.
We introduce social tokens: learned vectors derived from video frames, that are inserted into a frozen LLM to improve reasoning about social interactions and relations. Our approach adapts standard VLM training methods while modifying the interface between a visual encoder and LLM to better integrate social cues.
Methods
Setup and notation
Let \(L\) be our large language model and \(V\) be a visual encoder (e.g. DINOv2 or CLIP). We assume we can extract inputs from our video frames, which we refer to as \(\mathcal{F} = \{ F_1, \ldots, F_m \}\) and a time-aligned transcript \(\mathcal{W} = \{ W_1, \ldots, W_n \}\) that together depict social interactions. Tokenizing the transcript with \(L\)'s tokenizer yields \(\{ t_1, \ldots, t_k \}\).Our goal is to use \(V\) to build visual embeddings that are socially aligned. We take these embeddings, project via an MLP, and concatenate them with the token representations in \(L\) as social tokens. We tune the encoder \(V\) and projector to align the representations across the two models and improve multimodal understanding for social interactions. Our design is flexible and can be extended to further modalities like audio.
Finetuning the visual encoder
We begin by finetuning our visual encoder \(V\) on the frames \(\mathcal{F} = \{ F_1, \ldots, F_m \}\) from our dataset using a self-supervised reconstruction task such as the DINO loss. This step encourages \(V\) to encode fine-grained social cues that will be useful downstream. These finetuned \(\texttt{[CLS]}\) embeddings are what we refer to as social tokens: representations that are more closely aligned to social interactions. For each frame \(F_j\), we take the social token as a frame-level visual representation \(v_j\). We then finetune DINOv2 using the teacher-student self-distillation objective.Local and global social tokens
From the transcript, we extract nouns and verbs via POS tagging, following prior work showing that these parts of speech contain rich information for social scene understanding. Restricting to nouns and verbs encourages social alignment and mitigates common VLM failures such as overlooking social context. For each such word occurrence at time \(\tau\), we select the nearest frame \(F_j\) and compute its embedding \(v_j\). An MLP projector g(·) maps \(v_j\) into \(L\)'s embedding space, yielding a local social token \[ \texttt{[SOC-L]}_p = g(v_j) \] associated with token position p of the noun/verb. We define the global social token as the average of local tokens in the utterance:\[ \texttt{[SOC-G]} = \frac{1}{|\mathcal{P}|}\sum_{p\in\mathcal{P}}\texttt{[SOC-L]}_p \]
We construct the input sequence by prepending the global social token, \(\texttt{[SOC-G]}\), and inserting each local social token, \(\texttt{[SOC-L]}_p\) immediately after its corresponding text token position \(p\):
\[ t_p: \{ \texttt{[SOC-G]}, t_1, t_2, ..., t_p, \texttt{[SOC-L]}_p, ..., t_k \} \]
Training objective and inference
We freeze \(L\) and optimize the parameters of \(V\) and the projector \(g\) only. Given the augmented sequence, we apply standard next-token cross-entropy over text tokens; losses for the inserted \(\texttt{[SOC-*]}\) tokens are masked out. Gradients flow through the inserted social tokens into \(g\) and \(V\), aligning visual embeddings with \(L\)'s token space.At test time, we repeat noun/verb extraction, frame selection, projection, and token insertion, and then decode with \(L\). The design is modality-agnostic and can be extended by adding an audio encoder and projector in parallel.
Social tokens improve next-word prediction
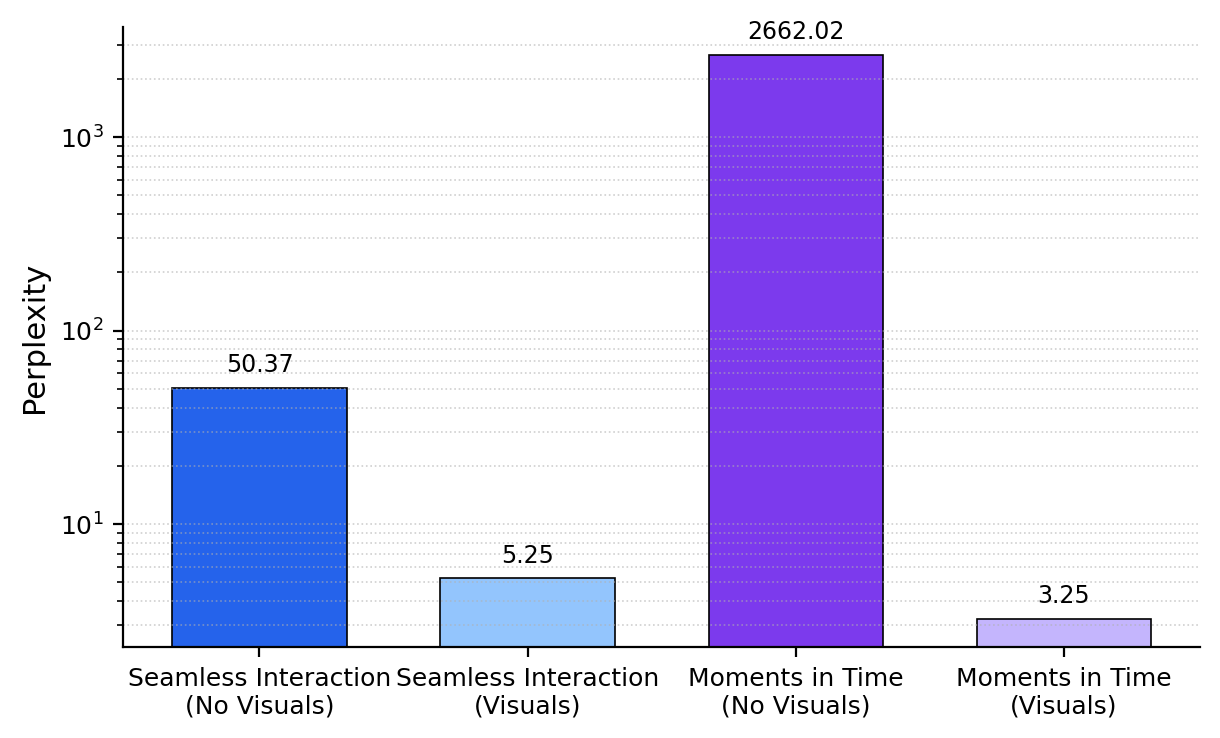
We measure perplexity of generated predictions from Gemma-2, tuned with social tokens and without social tokens. The perplexity is measured on a held-out dialogue set from the Seamless Interaction dataset (left) and a held-out caption set from the odd-one-out task (right). We find that including social tokens leads to a dramatic improvement in the model's ability to predict further social tokens.
Attention Scores of Social Tokens
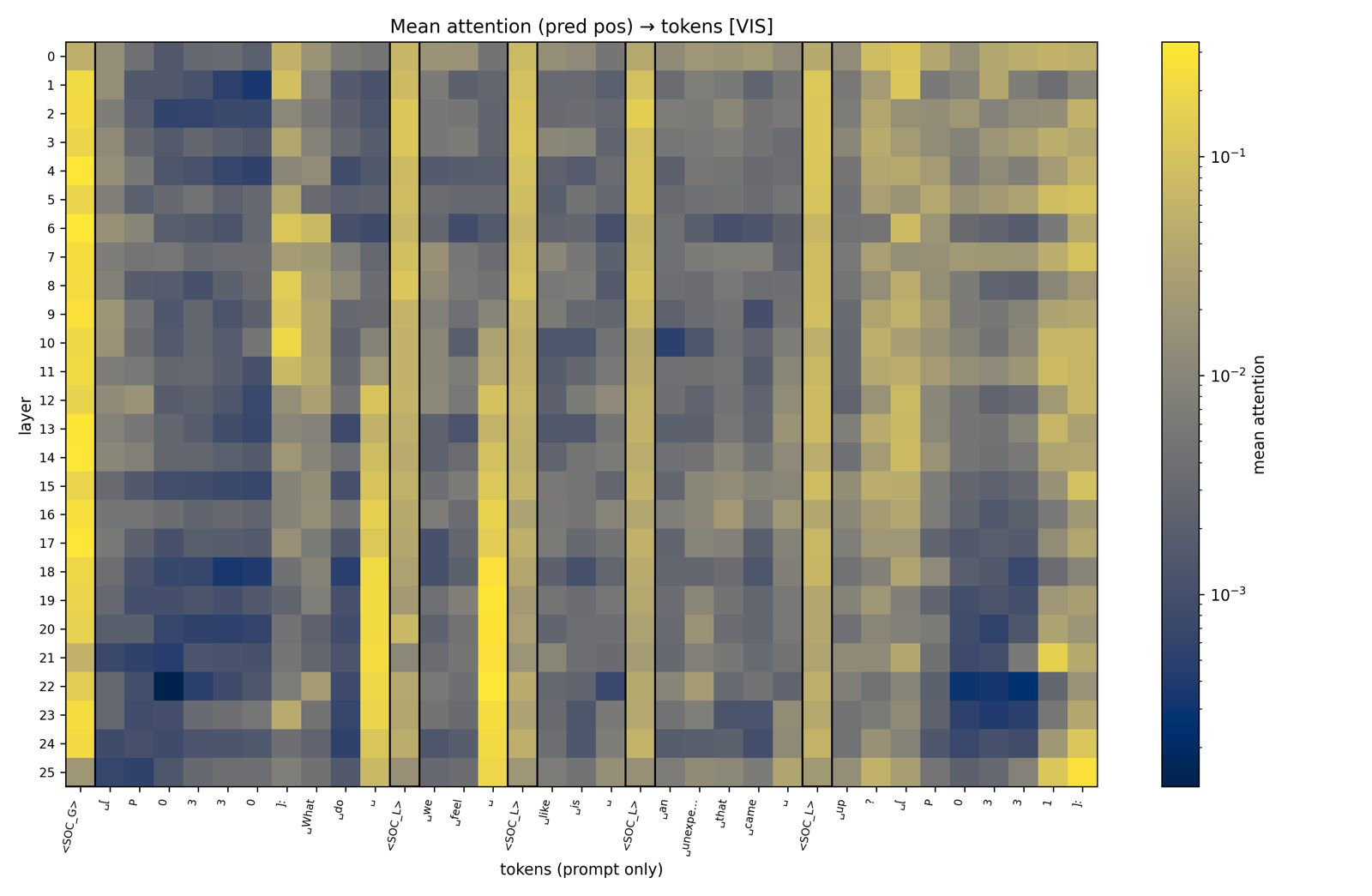
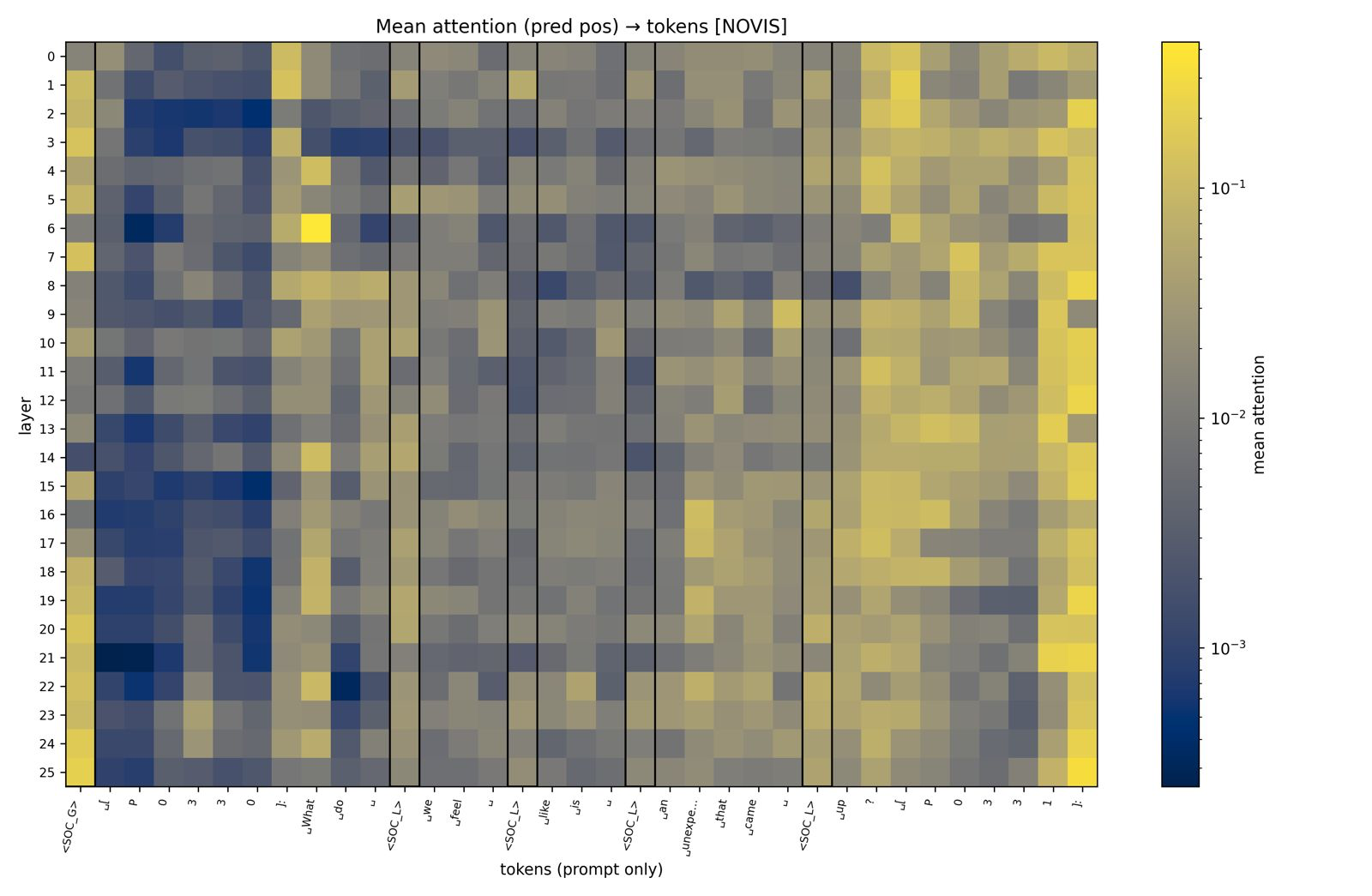
We analyze the attention maps from attention layers to understand how much attention is given to social tokens. On the left, we show the results from a string of tokens while on the right, we include a baseline where social tokens are replaced with zero vectors to understand whether there is a positional bias. We find that global social tokens receive a large amount of attention and this is not due to a positional bias as seen from the right visualization.
Conclusion
In this work, we introduced social tokens, a new mechanism designed to improve LLM performance on social tasks by aligning socially informative visual encoders with language models. This approach yielded consistent improvements in social understanding across socially relevant datasets and enhanced alignment with human judgments. Future work will include deeper ablations and extension to other modalities (e.g., audio) to broaden performance gains.