Abstract
Deep learning models trained on computer vision tasks are widely considered the most successful models of human vision to date. The majority of work that supports this idea evaluates how accurately
these models predict brain and behavioral responses to static images of objects and natural scenes. Real-world vision, however, is highly dynamic, and far less work has focused on evaluating the
accuracy of deep learning models in predicting responses to stimuli that move, and that involve more complicated, higher-order phenomena like social interactions. Here, we present a dataset of natural
videos and captions involving complex multi-agent interactions, and we benchmark 350+ image, video, and language models on behavioral and neural responses to the videos. As with prior work, we find that
many vision models reach the noise ceiling in predicting visual scene features and responses along the ventral visual stream (often considered the primary neural substrate of object and scene recognition).
In contrast, image models poorly predict human action and social interaction ratings and neural responses in the lateral stream (a neural pathway increasingly theorized as specializing in dynamic, social vision).
Language models (given human sentence captions of the videos) predict action and social ratings better than either image or video models, but they still perform poorly at predicting neural responses in the
lateral stream. Together these results identify a major gap in AI's ability to match human social vision and highlight the importance of studying vision in dynamic, natural contexts.
Methodological Overview
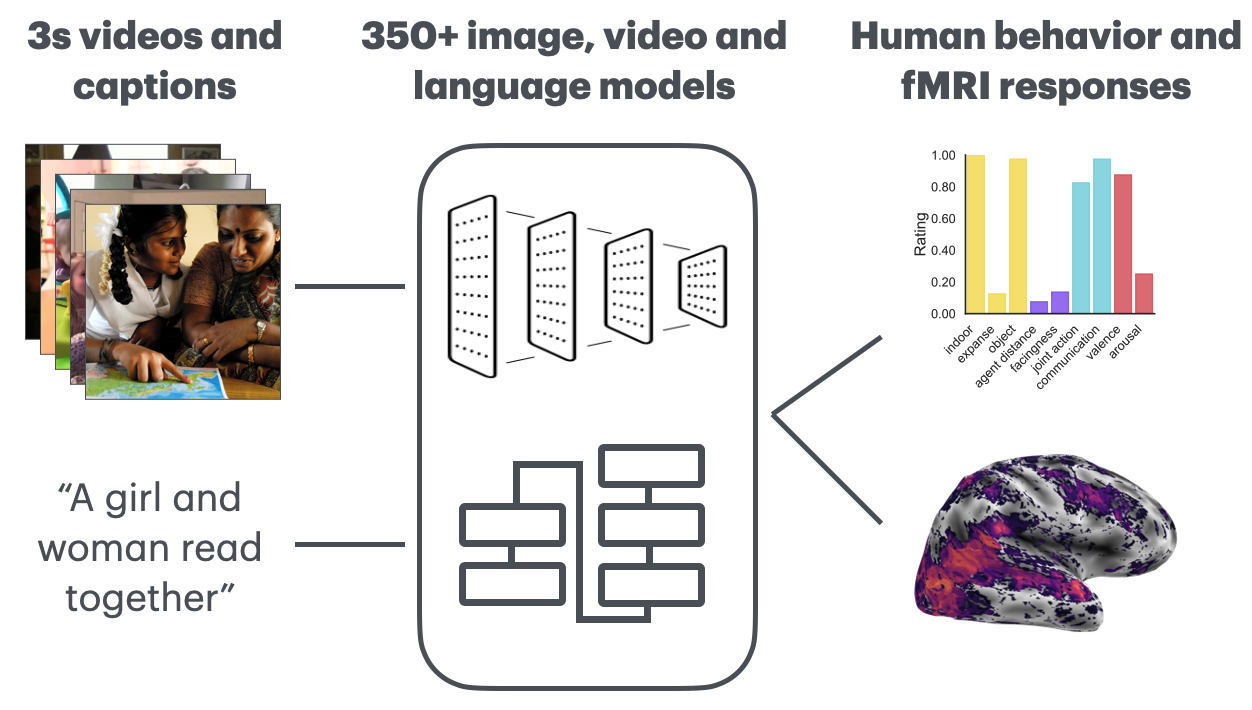
We extract representations from over 350 image, video, and language Deep Neural Network (DNN) models based on 3-second video inputs of human social actions or their captions. We then use model representations from each layer of the DNN's to predict human behavioral ratings and the neural responses recorded using fMRI of the subjects watching the videos.
Prediction Performance for human behavioral ratings and neural responses
In evaluating the benchmark of models, we compared how the different model classes (image, video, or language) performed on average at predicting behavioral ratings. We note that due to the larger number of image models tested,the best performing model is biased towards the image models. Despite this, we see a large amount of similarity between the different modalities. We find that for the visuospatial ratings (spatial expanse, interagent distance, and agents facing), no model class is substantially better on average (p>0.05), but for each rating the top performing model is an image model.
As in behavior, we can compare the average performance of the models across modalities. We evaluate performance in Regions of Interest (ROIs). We find that for several mid-level ROIs (MT, EBA, and LOC), video models dramatically outperform image models (ps<0.001). In both early visual cortex and high-level lateral regions(pSTS and aSTS), the quantitative performance gain is moderate and not significantly different (ps>0.05), and the best performing model is an image model.
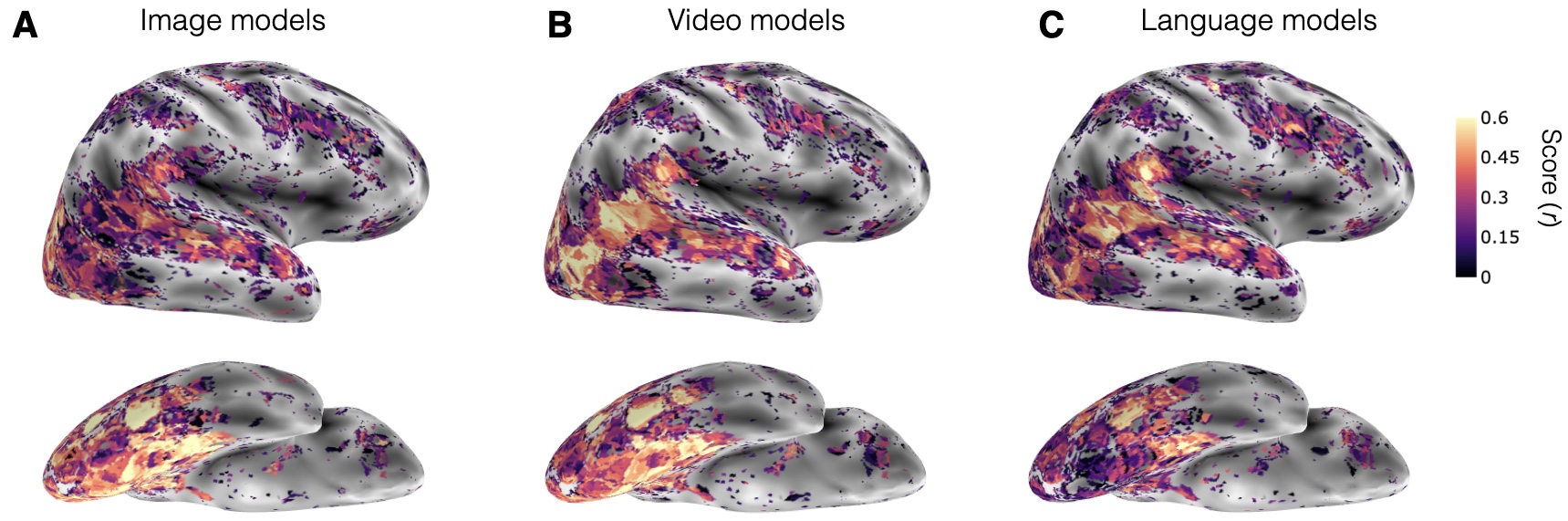
We further compared the models on other factors such as architecture and training. Within the image models, we do not find a notable difference in performance for models with either convolutional or transformer architectures or trained through supervised or self-supervision objectives.
Conclusion
Overall, we found a notable gap in all models’ ability to predict human responses. However, there are differences in the models that are best able to predict thebrain versus behavior. In particular, language models tend to be the best models of human behavioral ratings, while videos models best predict responses in lateral brain regions.
Citation
Garcia, K., McMahon, E., Conwell, C., Bonner, M. F., & Isik, L. (2025). Modeling Dynamic Social Vision Highlights Gaps Between Deep Learning and Humans. In International Conference on Learning Representations (ICLR).
🏆 Best Oral Presentation Award, LatinX in AI Workshop @ ICML 2024
📰 Featured in Media: The Wall Street Journal, JHU Hub, Popular Science, Marketplace